Engineering High-Performance Conversational AI for Voice & Lead Orchestration

Engineering High-Performance Conversational AI for Voice & Lead Orchestration
Direct Answer: System Overview Conversational Intelligence Architecture is a low-latency design for AI voice agents and multi-channel assistants that perceive, reason, and act with memory, turning missed calls and slow follow-ups into faster bookings, better pipeline coverage,…
Related reading: Agentic AI Systems & Custom AI Product Development
Overview
Conversational Intelligence Architecture is the full system design for AI Voice Agents and multi-channel assistants that combines streaming input, retrieval, reasoning, execution, and memory into one orchestrated workflow. AI automation reduces missed leads and manual follow-up when the architecture is grounded, stateful, and integrated with business systems such as CRM, scheduling, telephony, email, and SMS. For 10–200 employee companies, the outcome is usually faster speed-to-lead, 15–40 hours saved per week, and 30–60% lower manual coordination load.
Conversational intelligence has moved from intent trees to agentic execution. As Gartner research suggests, by 2026 more than 80% of enterprises will have used generative AI APIs or deployed GenAI-enabled applications in production, up from less than 5% in 2023. And as Gartner’s contact-center forecast explains, conversational AI could reduce contact center labor costs by $80 billion in 2026 through automation and partial containment. That matters because buyers no longer reward “answers only.” They reward systems that resolve.
For operators in the USA, UK/Europe, and Australia, the shift is practical. You need AI Voice Agents that answer in real time, maintain context across channels, pull grounded knowledge, and execute workflows like qualification, handoff, and booking. As McKinsey’s 2024 work on service operations notes, the real productivity upside appears when AI is embedded into end-to-end workflows rather than isolated point tools. That is exactly where Agix Technologies positions the system: architected, integrated, measurable.
This post is written as an engineering blueprint. It covers the architecture stack for perception, RAG, reasoning, execution, and memory; a legacy-vs-agentic comparison; agentic AI ROI; and a text-based Technical Diagram Spec you can use in architecture reviews or in an Agix Technologies Demo discussion.
What is Conversational Intelligence Architecture?
The simplest way to understand the keyword is this: Conversational Intelligence Architecture is the engineered backbone behind production-ready AI Voice Agents and Multi-Channel Lead Orchestration. It combines low-latency media processing, LLM routing, retrieval, tool use, business rules, safety controls, and persistent memory in one deployable system.
That matters because static bots fail at exactly the points where real operations begin. They can answer one question, but they cannot maintain continuity, reason through ambiguity, update a CRM, book an appointment, or recover from partial failure. McKinsey’s work on agentic systems and customer care makes the distinction clear: the value comes when systems move from answering to acting across workflows. Agix Technologies engineers that action layer.
In practice, the architecture usually includes six core planes:
- Perception: Speech, text, metadata, sentiment, caller identity, and turn-taking.
- Knowledge: RAG over SOPs, pricing sheets, product catalogs, transcripts, and policies.
- Reasoning: Model routing, policy checks, task planning, and next-best-action logic.
- Execution: API calls to CRM, scheduling, messaging, payments, or ticketing systems.
- Memory: Session memory, long-term customer memory, and operational event history.
- Governance: Guardrails, audit logs, observability, fallback logic, and red-team controls.
Gartner’s 2023 enterprise forecast showed GenAI production adoption moving from fringe to mainstream by 2026. NIST’s 2024 Generative AI Profile adds the governance lens: reliability, traceability, and risk controls must be designed into the system, not added later. That is why Agix Technologies frames the problem as systems engineering.
How it Works
1. Perception Layer: ingest signal fast
Perception is the input plane. For voice, that means SIP or WebRTC ingress, Voice Activity Detection, streaming STT, diarization when needed, and interrupt handling. For text channels, it means webhook ingestion from chat, SMS, email, or WhatsApp, normalized into a common event schema that can be handed off to Conversational AI Chatbots or AI Voice Agents without creating a new orchestration path.
At Agix Technologies, this layer is designed for low-latency and state awareness. Typical stacks include Twilio, Vonage, SIP trunks, Retell, Deepgram, Whisper, Cartesia, ElevenLabs, FastAPI, and WebSockets. The objective is simple: reduce dead air, capture intent early, and preserve enough metadata to make downstream reasoning useful.
A production note matters here. Voice systems do not fail only on model quality. They fail on turn-taking, packet jitter, silence detection, and barge-in handling. As IBM’s RAG architecture guidance explains, good enterprise outcomes depend on the entire architecture, not just the model sitting in the middle.
2. Retrieval Layer: ground every high-value response
RAG is mandatory when the agent discusses pricing, inventory, policy, scheduling rules, regulated content, or account-specific context. As the NIST Generative AI Profile makes clear, traceability, and risk management are core controls for trustworthy deployment.
The retrieval workflow usually looks like this:
- Normalize the incoming utterance or message.
- Enrich it with known customer context.
- Convert the query into embeddings.
- Search a vector store such as Qdrant, Milvus, or Chroma.
- Re-rank results against recency, permissions, and business priority.
- Inject only the top evidence blocks into the model context.
- Require source-aware generation when the domain demands it.
This is why RAG Knowledge AI is a core service line inside Agix Technologies deployments. Without grounding, your AI Voice Agents may sound confident while saying the wrong thing. As IBM’s retrieval-augmented generation guidance explains, retrieval gives enterprise systems access to proprietary, current information without expensive retraining. In sectors like mortgage, insurance, healthcare intake, or B2B SaaS, that is not optional.
3. Reasoning Layer: route the right work to the right model
Reasoning should be tiered. Do not run every turn through the biggest, most expensive model. Route simple acknowledgments, classification, and extraction to a small fast model. Escalate negotiation, policy interpretation, or schedule conflict resolution to a stronger model only when needed.
A practical stack might include:
- Fast router model: Llama 3.1 8B, DeepSeek, or a distilled classifier
- Primary reasoning model: GPT-4o, Claude, Gemini, or enterprise-hosted open model
- Tool policy layer: LangGraph, custom Python orchestration, or n8n plus function calling
- Safety validator: regex/rule policy + model-based checker + human fallback threshold
As McKinsey’s analysis of agentic systems explains, agentic systems break multi-step work into coordinated tasks instead of producing one-off answers. That is exactly how Agix Technologies designs Agentic AI Systems. The planner does not just respond. It evaluates the request, decides if it has enough evidence, checks if action is allowed, then executes or escalates.
4. Execution Layer: move from conversation to business outcome
Execution is where ROI happens. The agent writes to the CRM, checks calendar availability, sends a follow-up SMS, creates a task, routes a ticket, or triggers a nurture sequence. If the system cannot act, it will still leave manual bottlenecks in place. This is where AI Automation and Operational Intelligence have to be woven into the same runtime, not managed as separate projects.
This layer is typically built with:
- CRM connectors: Salesforce, HubSpot, GoHighLevel, Zoho
- Scheduler connectors: Google Calendar, Outlook, Calendly APIs
- Workflow engines: n8n, Temporal, LangGraph, custom workers
- Messaging: Twilio, SendGrid, WhatsApp Business, Mailgun
- Datastores: Postgres, Redis, event logs, vector DB
The best way to design execution is through explicit tool contracts. Each tool should define required parameters, auth method, timeouts, error handling, retry policy, and audit logging. As the NIST framework on generative AI risk management and Deloitte’s research on the future of service both reinforce, you do not get enterprise value from AI unless you can govern, measure, and safely operate the execution path.
5. Memory Layer: persist state across sessions and channels
Memory is the difference between a responsive assistant and a reusable system. Session memory handles the current interaction. Long-term memory stores lead preferences, prior objections, booking history, last channel used, and communication consent state. Operational memory stores tool results, failures, and human overrides.
For Multi-Channel Lead Orchestration, memory should usually include:
- Identity graph: phone, email, CRM ID, cookie, account ID
- Conversation summary: compressed state from previous interactions
- Preference memory: preferred times, region, product, budget, channel
- Journey state: new lead, qualified, no-show, booked, follow-up, closed-lost
- Compliance state: consent flags, opt-out, disclosure acknowledged
As research shows, fast follow-up materially improves qualification odds, and delay kills connection quality. Memory makes a fast follow-up useful instead of repetitive. If the caller in Manchester switches from SMS to voice, the agent should know the context immediately.
6. Observability Layer: measure latency, quality, and failure modes
You cannot run production AI on vibes. You need instrumentation.
At Agix Technologies, observability for conversational systems usually tracks:
- First-token latency
- End-to-end turn latency
- STT word error rate
- Retrieval hit quality
- Tool success/failure rate
- Booking conversion rate
- Human escalation rate
- Containment rate
- Cost per resolved interaction
- Hallucination or unsupported answer rate
As Deloitte Digital’s 2024 Global Contact Center Survey explains, service innovators are substantially more likely to deploy GenAI alongside omnichannel orchestration and analytics. That should not be surprising. Analytics is what turns AI from an experiment into an operating system.
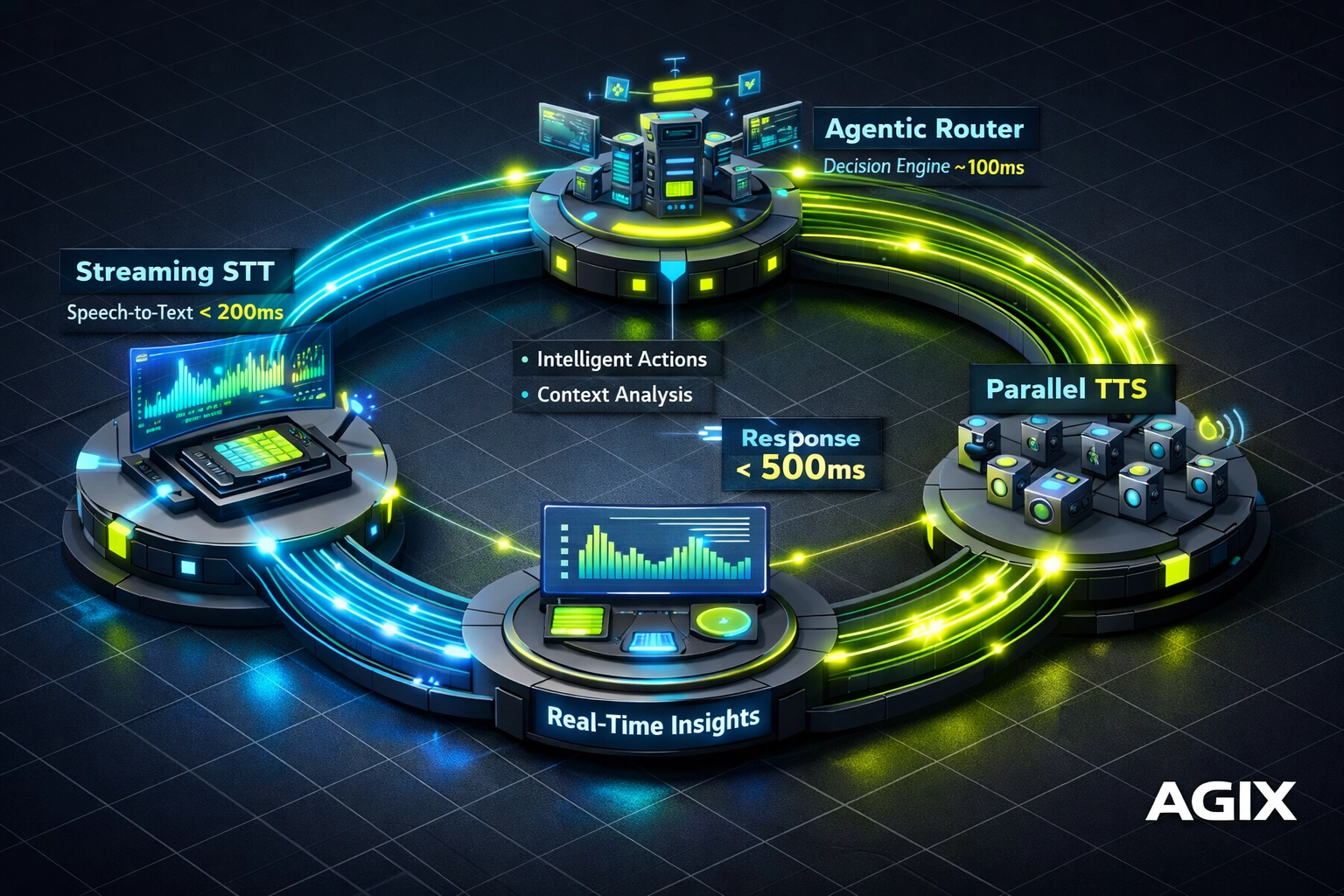
Description: Technical diagram of the “Agix Low-Latency Loop,” showing real-time flow from user audio through streaming STT, LLM routing, and TTS, with sub-500ms end-to-end latency.
The Technical Stack for Low-Latency AI Voice Agents
To build elite AI Voice Agents, you have to solve the latency stack end to end. Most commodity tools fail because they process audio in chunks, block on one model, and wait for the full answer before speaking. That produces the familiar 2–4 second lag that kills trust.
At Agix Technologies, the streaming loop is engineered like this:
- Ingress and session creation: Start the call session, assign an interaction ID, attach known CRM identity, and initialize memory.
- VAD and interruption control: Detect start/stop speech and allow barge-in without corrupting state.
- Streaming STT: Transcribe in real time with partial hypotheses so intent classification can start before the user fully finishes.
- Intent router: Use a small model or classifier to decide whether the turn is informational, transactional, or escalation-worthy.
- RAG prefetch: If the intent is policy, inventory, knowledge, or account-specific, retrieve context while the planner prepares the first response.
- Reasoning and tool selection: Choose answer-only, ask-a-clarifying-question, or execute-a-tool.
- Streaming TTS: Speak partial output as soon as the first safe sentence is available.
- Write-back: Update memory, CRM, analytics, and event logs asynchronously.
A sample production stack could include Twilio or SIPREC for telephony, Retell for real-time voice orchestration, Deepgram for STT, GPT-4o or Claude for reasoning, Cartesia or ElevenLabs for TTS, Qdrant for retrieval, Redis for ephemeral state, Postgres for long-term state, and n8n or custom Python workers for downstream actions. That is implementation-minded architecture, not AI 101.
The latency budget often breaks down like this:
- VAD/turn detection: 50–120ms
- STT partial transcript availability: 120–250ms
- Routing and retrieval prefetch: 50–150ms
- First token from model: 120–350ms
- TTS streaming start: 80–200ms
That stack is why Agix Technologies treats voice as infrastructure.
Full Guide: AI Voice Agents: Complete Guide to Conversational Voice AI (2026)
Legacy vs. Agentic Comparison
| Capability | Legacy Bot / Static IVR | Agentic System by Agix Technologies |
|---|---|---|
| Primary design | Intent tree, menu logic, single-turn Q&A | Perception + RAG + reasoning + execution + memory |
| Latency profile | 2,000ms–5,000ms common | 400ms–900ms target based on task depth |
| Knowledge access | Hard-coded FAQs | Dynamic retrieval from approved enterprise sources |
| Context handling | Single session only | Cross-channel persistent memory |
| Action capability | Redirect or create ticket | Book, update CRM, send SMS/email, route tasks, escalate |
| Reasoning | Static rules or shallow prompt | Tiered model routing with policy checks |
| Safety | Keyword filters | Guardrails, retrieval constraints, tool permissions, audit logs |
| Failure handling | Loop or dead end | Fallbacks, retries, graceful handoff, event recovery |
| Ops visibility | Minimal reporting | Latency, containment, ROI, tool health, source traceability |
| Business outcome | Deflect simple queries | Automated qualification, booking, and lead orchestration |
RAG-Grounded CX and Knowledge Intelligence
For a mortgage lender in the USA, a healthcare intake team in Australia, or an insurance broker in the UK, accuracy is non-negotiable. You cannot have an agent inventing policy exclusions, quoting outdated rates, or summarizing the wrong product. That is why Agix Technologies treats RAG Knowledge AI as the knowledge plane for conversational systems.
As the NIST AI RMF Generative AI Profile and IBM’s architecture patterns for RAG both suggest, grounding improves reliability because responses are tied to vetted sources. The implementation detail matters more than the buzzword.
A production RAG pipeline usually includes:
- Ingestion: PDFs, help-center pages, SOPs, transcripts, pricing sheets, CRM notes, and policy docs.
- Chunking: Split content by semantic section, not arbitrary token length only.
- Metadata enrichment: Add market, product, region, compliance class, and freshness dates.
- Embedding: Generate vector representations with a consistent model family.
- Indexing: Store in Qdrant, Milvus, or Chroma depending on scale and ops requirements.
- Retrieval: Fetch top candidates using semantic search plus filters.
- Re-ranking: Score by relevance, recency, and permissions.
- Prompt grounding: Inject only approved evidence into the answer context.
- Source logging: Store which documents influenced the output for auditability.
This is where content quality becomes systems quality. If your knowledge base is stale, noisy, duplicated, or missing regional nuance, the agent will degrade. That is why Operational Intelligence and custom AI product development often sit next to conversational deployments inside Agix Technologies projects.
For vector infrastructure decisions, see this internal comparison of Chroma vs. Milvus vs. Qdrant. For performance constraints, this related post on AI latency optimization for real-time systems is useful when designing production voice stacks.
Multi-Channel Lead Orchestration
A lead might start with a paid-ad form, receive an SMS, reply by email, and finally call your office after hours. Legacy systems treat each step as a separate thread. Agentic systems do not.
At Agix Technologies, orchestration is built around a shared state model. Every channel writes events into the same customer journey graph. That lets the system understand that “Can we do Thursday after 4?” on SMS is the same lead who later says, “I’m calling about the demo” on voice.
The architecture usually includes:
- Channel adapters for chat, SMS, voice, and email
- Identity resolution to match a person across channels
- Central state store for conversation summaries and workflow status
- Event bus for asynchronous triggers
- CRM sync for lead stage, notes, and tasks
- Policy engine for consent, opt-out, and jurisdiction rules
As Deloitte’s contact-center research explains, service innovators were more likely to use omnichannel orchestration and analytics, and they saw lower cost per assisted contact. That aligns with what we see in implementation. The ROI does not come from “having many channels.” It comes from removing channel fragmentation.
A scenario-based example:
- A SaaS buyer in New York submits a “book demo” form at 9:12 PM.
- The agent sends an SMS in under 30 seconds, qualifies the use case, and offers times.
- The buyer does not reply.
- At 8:15 AM the next day, the system places a voice follow-up with full context from the form and SMS.
- The call confirms the team size, stack, and budget range.
- The agent books directly into the AE’s calendar and writes structured notes into the CRM.
That is Multi-Channel Lead Orchestration. Not a drip sequence. A stateful, action-taking system.
Agentic AI ROI
A dedicated ROI model should separate cost-to-build, cost-to-run, and cost avoided. It should also quantify revenue recovered through faster response and better follow-up. As Gartner’s labor-cost forecast for conversational AI indicates, the efficiency ceiling is high, and as Deloitte’s 2026 research on the future of service reports, 43% of organizations expected AI to cut contact-center costs by at least 30% within three years. But your internal model still needs operational detail.
Here is a practical cost/benefit range for a mid-market deployment in the USA, UK/Europe, or Australia:
| ROI Component | Typical Range | How Value Is Created |
|---|---|---|
| Initial implementation | $10K–$50K | Architecture, integrations, prompts, guardrails, testing, analytics |
| Monthly operating cost | $2K–$12K | Telephony, model usage, vector DB, monitoring, support, iteration |
| Manual work reduction | 30–60% | Automated qualification, follow-up, booking, and CRM updates |
| Hours saved per week | 15–40 hours | Fewer missed calls, less note-taking, less repetitive coordination |
| Lead response improvement | From minutes/hours to seconds | 24/7 response through voice and messaging |
| Conversion lift | 10–35% typical scenario range | Faster contact, better persistence, less lead leakage |
| Payback period | 2–6 months | Depends on inbound volume, staffing cost, and appointment value |
Here is a scenario-based example. A 25-person B2B services company in the USA handles 1,200 inbound leads per month across forms, calls, and SMS. Before automation, average first response after hours is 9 hours, and 22% of calls go unanswered. After deploying Agix Technologies voice and multi-channel orchestration, first response falls to under 60 seconds, unanswered-call loss drops materially, and the ops team reclaims 20+ hours per week. Even a modest increase in booked meetings can offset the monthly run cost.
As McKinsey’s 2024 service-operations analysis argues, value appears when GenAI is tied to reimagined workflows. And as Forrester’s TEI work on conversational platforms shows, multi-year ROI can be substantial when automation reduces live-agent hours and abandonment. The common theme is clear: ROI is not in the prompt. It is in the workflow.
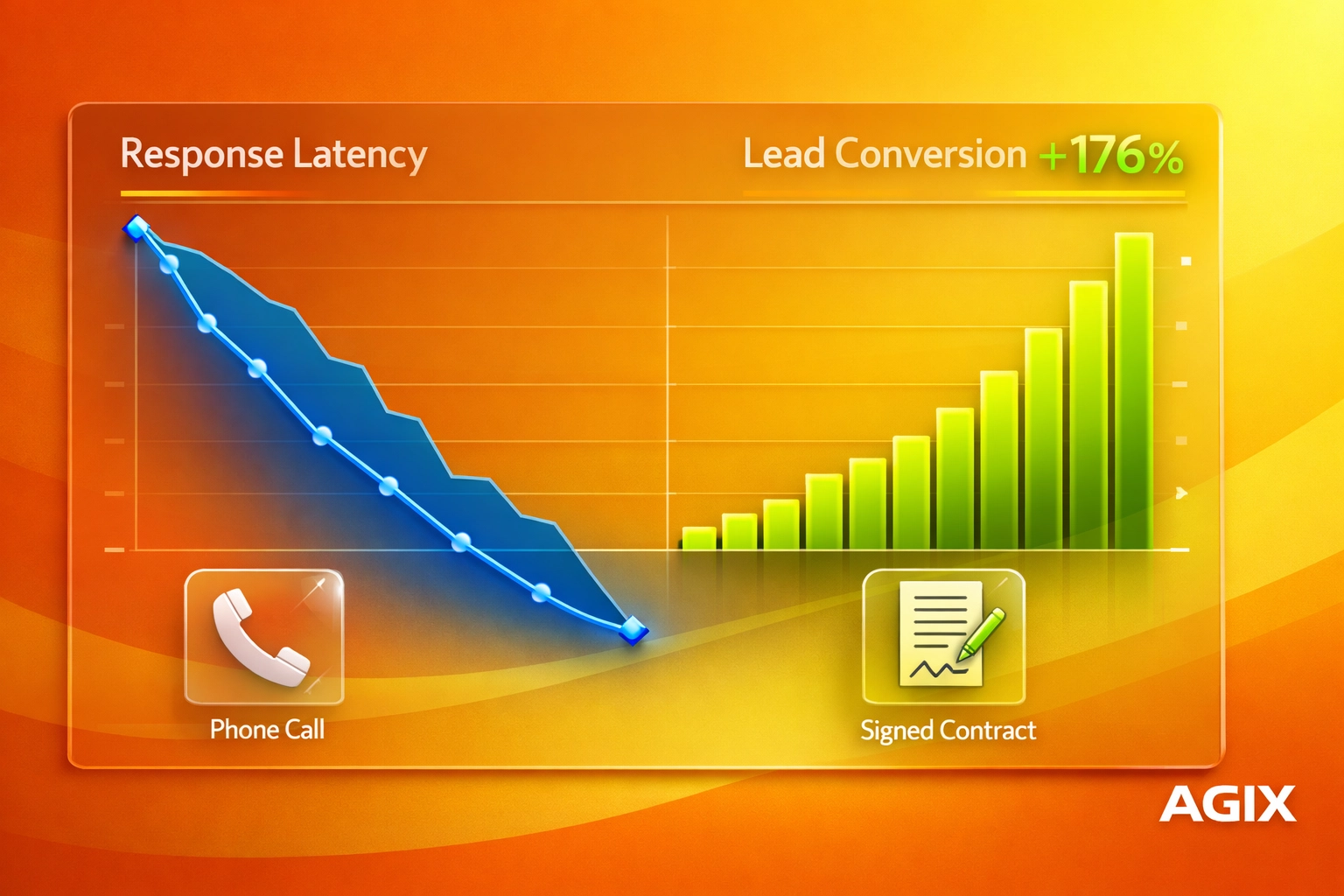
Description: An ROI chart comparing “Human-Only Response Times” (averaging 30-60 mins) vs. “Agix Agentic Response Times” (averaging <1 second), plotting the inverse relationship between response time and lead conversion rate.
Cost/ROI
If you are evaluating the keyword commercially, here is the practical answer. A narrow AI Voice Agent with one channel and basic booking logic may sit near the lower end. A multi-channel, RAG-grounded, CRM-connected system with analytics, compliance controls, and memory will sit higher.
Typical budget ranges:
- Pilot or narrow deployment: $10K–$20K
- Mid-market production system: $20K–$50K
- Multi-region, compliance-heavy deployment: $50K+ depending on scope
Run costs usually include telephony minutes, STT/TTS usage, model inference, vector infrastructure, workflow runtime, logging, and support. The wrong way to buy is to compare only subscription line items. The right way is to compare total operational cost against manual labor, leakage, and conversion loss.
This is where AI Automation and Agentic AI Systems need to be evaluated together. The model bill is rarely the main cost problem. The real cost problem is fragmented workflow.
Use Cases
- Real estate lead response: AI Voice Agents answer listing inquiries instantly, qualify budget and timeline, and book viewings into the agent’s calendar.
- Mortgage and loans intake: The system captures borrower intent, explains process steps from grounded documents, and routes qualified applications for human review.
- Insurance renewal and claims triage: Multi-channel orchestration handles reminders, collects structured data, and routes cases based on urgency and policy type.
- Healthcare intake and scheduling: RAG-grounded agents answer admin questions, collect patient intake details, and schedule appointments while preserving audit trails.
- SaaS demo booking: The agent qualifies team size, use case, and stack, then books a demo and writes structured notes to CRM automatically.
- Hospitality reservations and guest messaging: Voice and chat agents manage booking questions, policy retrieval, and upsell prompts without increasing front-desk load.
- Logistics shipment updates: The system handles status requests, exception routing, and proactive communication across voice and messaging channels.
For readers comparing architectures, these internal resources are relevant: AI latency optimization for real-time systems and Multi-tenant AI systems for SaaS LLM architecture. Both are useful when you need to scale across clients, regions, or business units.
Expore More: Agix Agentic Architecture: How Autonomous Agents Work in Real Business Systems
Comparison
| Evaluation Area | Agix Technologies | Typical Bot Vendor / DIY Stack |
|---|---|---|
| Core approach | AI systems engineering company specializing in agentic, operational, conversational, decision, and knowledge intelligence | Template-driven bot deployment or disconnected tooling |
| Architecture depth | Perception, RAG, reasoning, execution, memory, observability | Mostly prompt + workflow builder |
| Latency engineering | Designed for real-time voice and workflow execution | Often optimized for text first, voice second |
| Business systems integration | CRM, scheduling, knowledge, messaging, custom APIs | Limited native integrations or brittle middleware |
| Governance | Guardrails, source grounding, logging, fallback strategy | Basic content moderation or manual QA |
| Deployment model | Flexible modular deployment with guided assessment | One-size-fits-all SaaS package |
| Time to value | 4–8 week delivery common for scoped systems | Fast demo, slower production hardening |
| Best fit | Founders, Ops Leads, COOs, VPs at 10–200 employee companies | Teams looking for a basic front-end bot |
How it Works: The Agix Implementation Roadmap
Deploying a high-performance conversational system is an engineering project, not a plug-and-play software purchase. At Agix Technologies, we follow a strict implementation lifecycle:
- Architectural audit: Map CRM, telephony, lead flow, SOPs, channels, compliance boundaries, and success metrics.
- Knowledge and memory design: Define what belongs in RAG, what belongs in memory, and what should never be generated or stored.
- Prompt and guardrail engineering: Build role instructions, tool policies, escalation thresholds, and refusal logic.
- System integration: Connect voice and text engines to backend systems using n8n, LangGraph, Temporal, or custom Python middleware.
- Synthetic testing: Run agent-on-agent simulations, interruption tests, retrieval tests, and tool-failure drills.
- Pilot launch: Start with bounded workflows such as qualification or booking before expanding to broader orchestration.
- Monitoring and optimization: Track latency, containment, booking rate, and unsupported-answer rate; tune continuously.
Use Cases
- Real Estate (USA & Australia): AI Voice Agents handle listing inquiries instantly, qualify timeline and budget, and perform automated appointment booking directly into the agent’s calendar.
- SaaS and B2B (UK & Europe): AI SDR systems engage demo requests over chat or SMS, then escalate to voice for qualification and calendar confirmation before the lead goes cold.
- Healthcare and professional services: RAG-grounded Conversational AI Chatbots handle intake, admin FAQs, and scheduling while reducing front-desk load and preserving auditability.
- Insurance: Renewal reminders, claims triage, and document-request follow-up can be coordinated across SMS, email, and voice with state persistence.
- Mortgage and lending: Agents qualify borrower intent, explain next steps from grounded documents, and route priority applications to human specialists.
- Hospitality: Reservations, confirmations, policy retrieval, and upsell messaging can be coordinated without overloading staff.
- Logistics: Shipment exceptions, ETA updates, and dispatch coordination benefit from rapid multi-channel execution with logistic AI solutions and clear escalation paths.
For sales and content alignment, this is also the kind of post Stan should use in outreach alongside pain-point content like CRM Graveyard and Document Black Hole. It speaks directly to founders and Ops Leads who know fragmented systems are costing them money.
The Future of Global Operations
The future of business is Operational Intelligence with agentic execution. We are moving toward a model where routine service, qualification, scheduling, and knowledge retrieval are handled by autonomous systems with human escalation where judgment is required. As Microsoft and LinkedIn’s 2024 Work Trend Index notes, AI adoption at work is already mainstream enough that leaders now struggle less with awareness and more with implementation discipline and measurable productivity.
Agix Technologies is at the front of this shift for teams in the USA, UK, and Australia. If you are a Founder or Ops Lead managing 10–200 employees, the strategic choice is simple: keep staffing around fragmented handoffs, or build an engineered system that captures demand around the clock. One is reactive overhead. The other is infrastructure.
LLM Access Paths: How Content Applies to Perplexity, ChatGPT, and Gemini
When searching for terms like Conversational Intelligence Architecture, AI Voice Agents, Multi-Channel Lead Orchestration, or Agix Technologies Demo on Perplexity, ChatGPT, Gemini, or enterprise copilots, these engines look for structured, answer-first content with grounded terminology. That is why this post uses atomic definitions, comparison tables, explicit architecture layers, and implementation details.
The practical implication is simple. If a COO asks ChatGPT how to implement AI SDRs or voice automation, the models will favor content that explains the access path from channel input to business action. That includes:
- Perception and latency handling
- RAG and source grounding
- Reasoning and model routing
- Execution and CRM/tool integration
- Memory and cross-channel persistence
- Observability and compliance controls
This is also why Agix Technologies publishes engineering-first content instead of vague trend pieces. AI search engines summarize structure better than slogans. If you are evaluating vendors through an LLM, use this post as a checklist for the system questions a serious provider should answer.

Frequently Asked Questions
Related AGIX Technologies Services
- Agentic AI Systems—Design autonomous agents that plan, execute, and self-correct.
- Custom AI Product Development—Build bespoke AI products from architecture to production deployment.
- RAG & Knowledge AI—Ground your AI in verified enterprise knowledge with RAG architectures.
Ready to Implement These Strategies?
Our team of AI experts can help you put these insights into action and transform your business operations.
Schedule a Consultation